
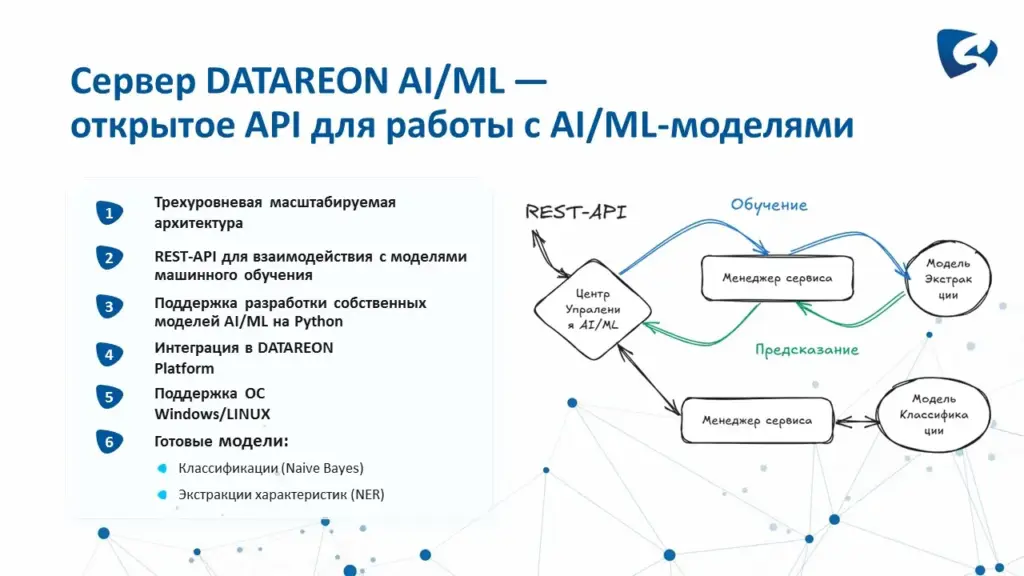
Сервер DATAREON AI/ML представляет собой набор сервисов и системных служб с трехуровневой масштабируемой архитектурой. В состав сервера входят центр управления моделями и сервис-менеджер, обеспечивающий возможность добавления моделей, их обучения, пополнения обучающих примеров и выполнения прогнозирования. Взаимодействие с внешними системами осуществляется посредством REST API. Сервер может функционировать как автономно, так и в составе корпоративного контура, а также интегрироваться с платформой DATAREON. Поддерживаются операционные системы Windows и Linux. Для целей тестирования предоставляется интерфейс Swagger (интерактивная документация API).
Сервер DATAREON AI/ML поставляется с моделями классификации и извлечения (экстракции) информации. Скрипты моделей реализуются на языке Python.
Модель классификации. Наивный байесовский классификатор
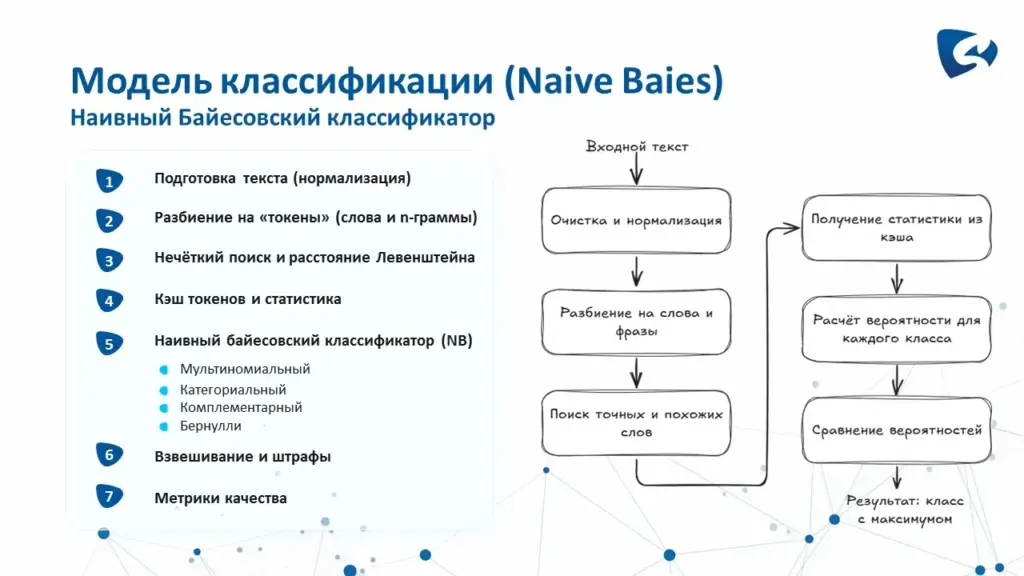
Модель классификации представляет собой гибридный классификатор, предназначенный для определения класса нормативно-справочной информации (НСИ). Основная задача модели — по текстовому наименованию номенклатурной позиции выявить наиболее вероятный класс классификатора на основе статистики встречаемости слов, устойчивых словосочетаний, шаблонов и сходных токенов, характерных для данного класса.
На первом этапе выполняется предварительная обработка текста (нормализация). Текст приводится к нижнему регистру для устранения шумов, связанных с различиями в написании прописных и строчных букв. Осуществляется специализированная обработка цифр, знаков препинания, разделителей и служебных символов. В составе модели применяются регулярные выражения (шаблоны) для поиска и замены символов, в частности для удаления шума, лишних пробелов, нестандартных символов и повторяющихся разделителей. Такая предварительная очистка позволяет привести различные варианты написания одной и той же номенклатуры к сопоставимому виду.
Далее производится разбиение текста на токены (слова и n-граммы) различных уровней. Используются как отдельные слова (униграммы), так и последовательности из нескольких слов: биграммы, триграммы и n-граммы большей длины. Это позволяет учитывать не только отдельные слова, но и контекст их употребления. Например, отдельное слово может встречаться в разных классах, тогда как устойчивое сочетание из двух или трёх слов может служить характерным признаком конкретного класса. Для каждого токена также может быть построена специальная маска (например, слово «дом123» преобразуется в маску, где цифры заменяются на специальный символ). Данный механизм способствует обобщению сходных токенов и распознаванию однотипных значений, различающихся только числовой частью.
Полученные токены проверяются с использованием нечёткого поиска на основе расстояния Дамерау-Левенштейна. Этот механизм позволяет оценить степень сходства двух слов и учитывать опечатки, перестановки символов, пропущенные или лишние буквы. Расстояние Дамерау-Левенштейна отражает минимальное количество операций (вставки, удаления, замены или перестановки соседних символов), необходимых для преобразования одного слова в другое. Слово, содержащее ошибку, как правило, характеризуется небольшим расстоянием Дамерау-Левенштейна и может быть распознано моделью как близкое совпадение.
Для ускорения нечёткого поиска применяется хеширование. Токены преобразуются в хеши и распределяются по специальным сегментам (хеш-бакетам), где группируются потенциально сходные слова и словосочетания. Это позволяет не сравнивать каждый токен со всеми словами из обучающей выборки, а быстро находить наиболее близкие по смыслу варианты. Указанный подход существенно ускоряет работу классификатора при большом количестве классов и значительном объёме накопленной статистики.
Токены и результаты их обработки сохраняются в кэше, который обеспечивает накопление статистики по классам и её оперативное обновление. Для каждого токена хранятся сведения о частоте его встречаемости в каждом классе, общей частоте, близких нечётких вариантах, а также связанных с ним масках и n-граммах. Благодаря этому модель может быстро пересчитывать вероятности при добавлении новых данных и использовать накопленную статистику без полного переобучения.
На следующем этапе используется наивный байесовский классификатор (NB — Naive Bayes). Он вычисляет вероятность встречаемости каждого токена в том или ином классе и на основе формулы Байеса определяет вероятность принадлежности номенклатурной позиции конкретному классу.
В модели классификации могут применяться различные варианты наивного байесовского классификатора:
- Мультиномиальный вариант учитывает частоту встречаемости токенов и хорошо подходит для текстов, в которых важна повторяемость слов.
- Категориальный вариант сравнивает распределение категорий и признаков.
- Комплементарный наивный байесовский классификатор эффективен при несбалансированных классах, когда одни классы представлены значительно большим количеством примеров, чем другие.
- Бернуллиевский вариант учитывает не только наличие токена в классе, но и его отсутствие, что может быть полезно для классов с характерным набором обязательных либо, напротив, нехарактерных признаков.
Для всех вариантов классификатора применяется сглаживание вероятностей. Оно необходимо для того, чтобы редкие или ранее не встречавшиеся токены не обнуляли итоговую вероятность класса. Без сглаживания один неизвестный токен мог бы привести к нулевой вероятности класса, даже если остальные части наименования НСИ однозначно указывают на этот класс. Сглаживание обеспечивает устойчивую работу модели с новыми наименованиями, опечатками, редкими артикулами и нестандартными формулировками.
На последнем этапе выполняется взвешивание результатов. Достоверные токены (точные совпадения) получают больший вес, тогда как токены с ошибками или нечёткими совпадениями штрафуются. Например, точное совпадение может иметь вес 1, а сходное слово с одной ошибкой — пониженный коэффициент (например, 0,5). Для n-грамм также могут задаваться отдельные веса, поскольку длинные устойчивые словосочетания часто являются более надёжным признаком класса, чем отдельные слова. Дополнительно могут учитываться априорные вероятности классов: если некоторый класс встречается в данных значительно чаще других, он может получать небольшое преимущество при прочих равных условиях.
Итоговая вероятность для каждого класса формируется на основе совокупности факторов: частот токенов, n-грамм, результатов нечёткого поиска, штрафов за ошибки, весов совпадений, априорных вероятностей и статистики, накопленной в кэше. После этого модель ранжирует классы по вероятности и возвращает внешней системе наиболее подходящий класс НСИ, а при необходимости — несколько наиболее вероятных вариантов с оценками уверенности. Такой гибридный подход позволяет сочетать скорость статистического классификатора, устойчивость к опечаткам и способность учитывать контекстуальные признаки номенклатурных наименований.
Для оценки качества работы модели рассчитываются стандартные метрики классификации. В первую очередь формируется матрица ошибок, показывающая, сколько объектов каждого фактического класса было отнесено моделью к каждому предсказанному классу. На основе матрицы ошибок вычисляются точность (precision), полнота (recall), F-мера и коэффициент корреляции Мэтьюса (Matthews correlation coefficient).
Точность показывает долю объектов, отнесённых моделью к определённому классу, которые действительно принадлежат этому классу. Полнота отражает долю объектов заданного класса, правильно найденных моделью. F-мера объединяет точность и полноту в единую сбалансированную оценку. Коэффициент корреляции Мэтьюса используется как более устойчивая интегральная метрика качества, особенно полезная при несбалансированных классах, поскольку учитывает, как правильные, так и ошибочные предсказания по всем классам.
Модель экстракции. Извлечение именованных сущностей
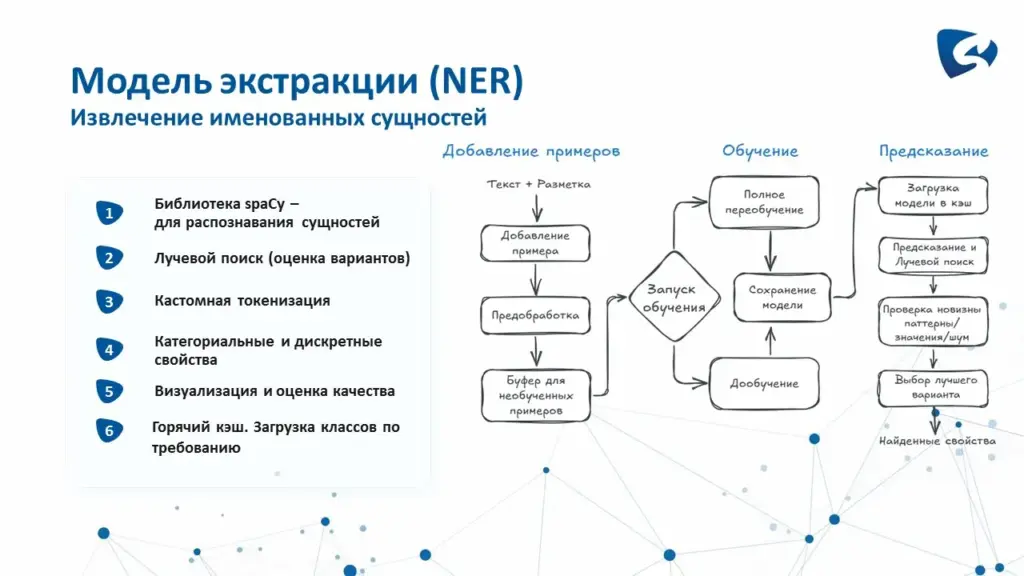
Модель экстракции предназначена для выделения сущностей и их свойств из наименования номенклатуры. Например, из строки «Модель iPhone 12, 128 ГБ» модель может извлечь две характеристики: «iPhone 12» как модель и «128 ГБ» как объём памяти.
Для решения этой задачи используется библиотека spaCy с собственной моделью распознавания именованных сущностей (NER — Named Entity Recognition). spaCy выступает в качестве основного инструмента обработки текста: она выполняет токенизацию строки, анализирует текстовую структуру и позволяет обучать модель на пользовательских данных. В сервисе применяется собственная обучаемая модель, настраиваемая под конкретные классы номенклатуры и их характеристики. В процессе обучения в модель добавляются размеченные примеры, указывающие, какие фрагменты строки являются значениями характеристик и к каким сущностям они относятся. После обучения модель используется для прогнозирования на новых наименованиях и возвращает найденные характеристики.
Модель выдаёт не единственный вариант разбора, а несколько возможных вариантов с оценками вероятности. Метод лучевого поиска (beam search) позволяет сравнить эти варианты и выбрать наиболее качественный результат. Такой подход особенно полезен в неоднозначных случаях, когда один и тот же фрагмент строки может интерпретироваться по-разному в зависимости от контекста, класса номенклатуры или набора доступных характеристик.
Кроме того, реализована собственная токенизация. Встроенная токенизация spaCy не всегда оптимальна для номенклатурных наименований, поскольку такие строки часто содержат сокращения, числовые значения, единицы измерения, артикулы, специальные символы и нестандартные разделители. Поэтому используется пользовательская токенизация, более гибко разбивающая строку на слова и токены с учётом пробелов и позиций символов в исходном тексте. Это позволяет точно определять границы характеристики в исходной строке.
В модели предусмотрены категориальные и дискретные свойства. Категориальные свойства хранят конкретные значения характеристик (например, цвет, тип материала, наименование модели). Дискретные свойства описывают не столько сами значения, сколько их шаблоны и паттерны. Для каждого свойства также ведётся счётчик встречаемости значений, что позволяет учитывать частотность и повышать качество последующих прогнозов.
Для контроля качества работы модели предусмотрены средства визуализации и оценки результатов. Используется матрица ошибок, а также рассчитываются основные метрики качества извлечения сущностей: TP (истинно положительные, корректно найденные значения), FP (ложноположительные, ложные срабатывания), FN (ложноотрицательные, пропущенные значения), BM (сущность найдена, но ей присвоена неверная метка). Эти показатели позволяют анализировать ошибки, выявлять проблемные классы и характеристики, а также принимать решения о необходимости дообучения.
Реализован механизм «горячего» кэширования, позволяющий хранить на диске практически неограниченное количество классов (ограниченное лишь ёмкостью дискового пространства). При этом в оперативную память загружаются только те классы, с которыми ведётся работа в текущий момент. Такой механизм загрузки по требованию обеспечивает рациональное использование ресурсов системы, не перегружает память и позволяет одновременно работать с большим количеством классов номенклатуры. Благодаря этому модель может масштабироваться на крупные справочники и использоваться в промышленных сценариях обработки НСИ.
Лицензирование и интеграционные сценарии
Лицензирование сервера DATAREON AI/ML осуществляется отдельно от лицензирования платформы DATAREON.
Сервер DATAREON AI/ML может быть использован в различных интеграционных сценариях. Для выполнения задач классификации, нормализации, семантического поиска и обогащения данных компания SOFROS разработала инструмент — сервис SOFROS AI/ML.
Интересны детали?
Смотрите запись вебинара на нашем канале
И обязательно подпишитесь на нас в социальных сетях, чтобы не пропустить новые полезные материалы, а также специальные акции для участников мероприятий.
