
Введение: ограничения простых алгоритмов сравнения строк
Организации нередко начинают борьбу с дублированием записей с применения простых алгоритмов, основанных на сравнении текстовых строк в предположении, что похожие строки соответствуют одной и той же сущности. Технически такой подход сводится к разбиению строк на подпоследовательности или токены, подсчёту числа совпадающих фрагментов и вычислению метрик сходства (расстояние Дамерау — Левенштейна, Джаро — Винклера, token ratio и аналогичных). Для каждой неканонической записи выбирается эталон с максимальным значением метрики. Однако подобные методы демонстрируют точность не выше 30–40 % ввиду низкой дискриминационной способности.
Рассмотрим конкретный пример: два прутка с обозначениями «ПК-РВХ» и «ПК-ПВХ» представляют собой различные единицы номенклатуры (круглого и квадратного сечения соответственно). Ошибочное отождествление таких позиций неизбежно приведёт к отгрузке некорректной номенклатуры и нарушению спецификации, что создаёт риски на производстве или в строительстве.
Цифровой шум в данных — различные префиксы, обозначения диаметра, сокращения из спецификаций поставщиков — порождает вариативность написания, с которой простые алгоритмы справляются неудовлетворительно. Порядок слов в наименовании также может варьироваться, а перестановки слов ведут к ошибкам при использовании традиционных методов сравнения строк. Различная длина строк, обусловленная наличием сокращений, дополнительно усложняет анализ.
Особую сложность представляет обработка русского языка, в котором одно и то же слово может быть записано множеством способов. Простые алгоритмы (прямое сравнение строк, регулярные выражения, методы Джаро — Винклера) не обеспечивают требуемой точности. Они либо не объединяют элементы, подлежащие объединению, либо ошибочно сливают различные элементы, как в приведённом примере с прутками.
Сервис SOFROS AI/ML: открытое API для работы с моделями машинного обучения
В ходе реализации проектов, связанных с нормализацией нормативно-справочной информации (НСИ), экспертами SOFROS был сделан вывод о недостаточности какого-либо одного инструмента. Необходим комплексный подход. В одних случаях эффективны шаблонные методы, позволяющие быстро выделять нормативы и стандартные параметры. В других — классическое машинное обучение. Для наиболее сложных формулировок применимы современные языковые модели, анализирующие даже неструктурированные описания. Такие модели требуют больших вычислительных ресурсов, но обеспечивают высокое качество результата.
Ни один метод не решает задачу самостоятельно. В связи с этим в сервисе нормализации SOFROS AI/ML применяется гибкое сочетание всех перечисленных подходов. Гибридный метод позволяет одновременно обрабатывать большое количество записей с высокой точностью.
На основе структурированных данных решаются прикладные задачи: поиск дублей, подбор аналогов, сопоставление со справочниками различных филиалов, интеграция в технологические процессы.
В контексте MDM-системы (Master Data Management) интеллектуальный сервис встраивается в существующий контур и автоматически обрабатывает все входящие данные. Для сотрудников процесс остаётся привычным: они работают в основной системе, однако каждая запись проходит интеллектуальную обработку — приводится к единому корпоративному формату, извлекаются и нормализуются атрибуты, проверяются значения по справочным данным, осуществляется валидация и контроль логических связей. В итоге в MDM поступает корректная запись, которую эксперт только утверждает. Далее запись становится доступной для всех взаимосвязанных систем, использующих единый номенклатурный справочник.
Важно подчеркнуть: интеллектуальный сервис нормализации SOFROS AI/ML не заменяет MDM-систему, а расширяет её возможности, снимая рутинную нагрузку с экспертов и автоматизируя нормализацию, проверку и структурирование данных.
В рамках развития сервиса были разработаны новые модели: модель семантического поиска, модель контекстного поиска, а также дополнительный класс для выделения персонально идентифицируемой информации (PII).
Модель семантического поиска: генерация с дополнительной выборкой
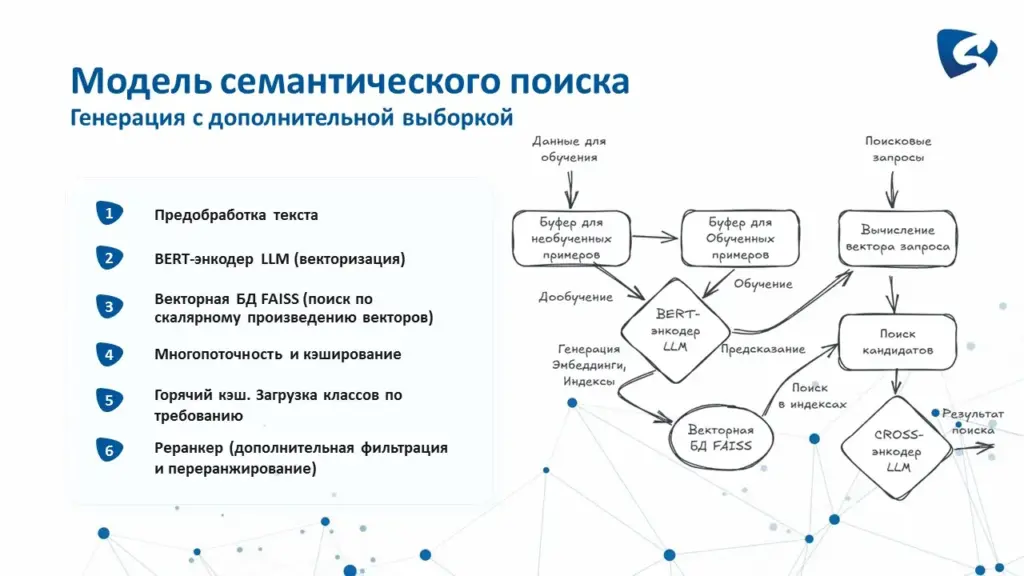
Модель семантического поиска решает задачу нечёткого и смыслового поиска с использованием алгоритмов больших языковых моделей (LLM). Она позволяет находить элементы, сходные по смыслу с исходным запросом (например, наименования НСИ, характеристики или значения характеристик), и ранжировать найденные результаты по степени релевантности.
На первом этапе выполняется предобработка текста: с помощью регулярных выражений удаляются лишние пробелы, проводится предварительная нормализация, при необходимости текст приводится к нижнему регистру. Для некоторых языковых моделей может дополнительно добавляться точка в конец коротких текстов с целью снижения вероятности ошибок при обработке кратких фраз.
Затем в работу включается BERT-энкодер — локально установленная языковая модель, осуществляющая векторизацию текста. Каждый текст преобразуется в вектор — набор чисел, отражающий его смысловое содержание. Если два текста близки по смыслу, их векторы располагаются рядом в векторном пространстве. Для оценки близости используется косинусная мера или скалярное произведение векторов.
Все данные, полученные на этапе векторизации, сохраняются в специализированной векторной базе FAISS. Эта база предназначена для быстрого поиска сходных векторов среди большого количества объектов. Например, среди десятков или сотен тысяч документов FAISS позволяет за доли секунды найти несколько наиболее близких к запросу элементов. В данной модели используется поиск по скалярному произведению: чем выше значение, тем ближе найденный элемент к исходному запросу.
Для ускорения работы применяются многопоточность и кэширование. Модель может одновременно вычислять оценки для нескольких пар «запрос — документ», распределяя вычисления по отдельным потокам. Поскольку построение вектора для текста является ресурсоёмкой операцией, результаты векторизации сохраняются в кэше. При повторном обращении к тому же тексту его вектор не вычисляется заново, а извлекается из сохранённого результата.
Дополнительно используется «горячий» кэш и загрузка классов по требованию. В память загружаются не все данные сразу, а только те классы или группы элементов, которые необходимы в текущий момент. Это снижает нагрузку на оперативную память и ускоряет работу системы при большом объёме справочной информации.
На последнем этапе подключается специально обученная модель — реранкер. Первичный поиск по векторной базе может возвращать зашумлённые результаты: элементы могут быть близки по общему смыслу, но не всегда точно соответствовать запросу. Реранкер выполняет вторую ступень фильтрации. Он принимает пару «запрос — документ» и оценивает, насколько найденный документ действительно релевантен запросу, выдавая точную оценку вероятности в диапазоне от 0 до 1. Для этого используется специализированная языковая модель — кросс-энкодер, которая анализирует запрос и найденный документ совместно, что позволяет лучше улавливать тонкие смысловые различия.
Таким образом, модель объединяет несколько технологий: Sentence Transformers для построения смысловых векторов, FAISS для быстрого поиска по векторной базе, нейросетевой реранкер для точной сортировки результатов, а также многопоточность и механизмы кэширования (обычного и «горячего») для ускорения обработки. Такая архитектура позволяет использовать модель в качестве готового движка для систем «вопрос-ответ», поиска сходных сущностей, номенклатуры, характеристик, значений характеристик и других категорий элементов, где требуется быстрый и точный семантический поиск.
Модель контекстного поиска: вызов инструментов веб-поиска
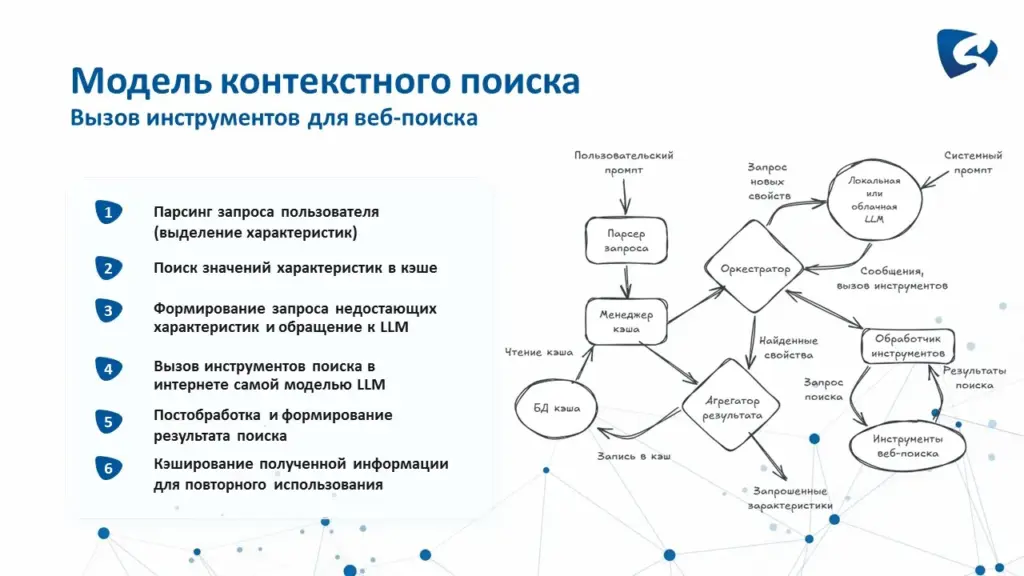
Модель контекстного поиска функционирует как интеллектуальный справочник характеристик товаров, используемый для дообогащения информации из интернета и возврата данных в машиночитаемом виде. Она принимает пользовательский запрос, анализирует его содержание и выделяет необходимые характеристики товара: наименование, категорию, параметры, свойства, возможные значения и другие признаки, полезные для справочника.
Работа модели начинается с парсинга запроса пользователя. Из входного текста извлекаются характеристики, уже явно указанные в запросе, а также определяются потенциально недостающие параметры, которые требуется найти дополнительно. Модель способна работать не только с характеристиками, уже присутствующими в системе, но и выявлять новые характеристики, существующие в открытых источниках, для последующего добавления их в справочник.
Для ускорения обработки используется механизм кэширования. Перед обращением к большой языковой модели система проверяет локальный кэш характеристик. Если пользователь запрашивает информацию о товаре или характеристике, которая уже была обработана ранее, готовые данные возвращаются из кэша. Это позволяет не вызывать LLM повторно и сокращает время ответа.
Менеджер кэша распределяет запросы между кэшем и LLM. Он определяет, какие характеристики уже известны и могут быть получены из кэша, а какие отсутствуют и требуют дополнительной обработки.
Для неизвестных или неполных характеристик формируется запрос к LLM. Взаимодействие с языковой моделью выполняется через библиотеку Ollama. Модель получает системную инструкцию, описывающую формат работы и ожидаемый результат, а также вопрос пользователя или сформированный внутренний запрос. На основе этой информации LLM определяет нужные характеристики и возвращает структурированный ответ.
Если языковой модели недостаточно собственных знаний для заполнения характеристик, она может инициировать вызов инструмента веб-поиска. В этом случае через саму LLM выполняется обращение к поисковой системе в интернете. Веб-поиск возвращает краткие релевантные результаты, после чего модель использует найденную информацию для уточнения или заполнения недостающих характеристик товара.
После получения ответа выполняется постобработка данных: результаты нормализуются, очищаются, приводятся к единому формату и подготавливаются для дальнейшего использования. На этом этапе могут удаляться дубликаты, уточняться наименования характеристик, значения могут приводиться к стандартному виду и формироваться итоговая структура ответа.
Затем полученная информация сохраняется в кэш. Это позволяет при повторных запросах к тем же товарам или характеристикам быстро возвращать уже найденные данные без повторного обращения к LLM и веб-поиску.
В итоге модель представляет собой связку локального кэша, большой языковой модели (через Ollama) и механизма вызова инструментов веб-поиска. Такая архитектура обеспечивает быстрое получение характеристик товаров, их дообогащение данными из интернета, выявление новых свойств и возврат результата в структурированном машиночитаемом виде.
Классификация персонально идентифицируемой информации (PII)
Классификация PII (Personally Identifiable Information) — это систематический процесс разделения персонально идентифицируемой информации на категории в зависимости от уровня чувствительности, критичности, потенциальных рисков для субъекта данных при компрометации, а также требуемых мер защиты. Такая классификация позволяет унифицировать подходы к обработке, хранению, доступу и уничтожению PII в соответствии с законодательством (например, GDPR, CCPA, Федеральный закон № 152-ФЗ) и политиками информационной безопасности организации.
Цели применения классификации PII
- Управление рисками — выявление и оценка вероятного ущерба для субъекта данных (финансового, репутационного, физического) в случае утечки или неправомерного использования PII.
- Дифференциация мер защиты — назначение соответствующих технических и организационных мер (шифрование, контроль доступа, маскирование, аудит) для каждой категории PII.
- Упрощение управления данными — стандартизация процессов обработки, хранения и удаления PII на основе единой классификационной матрицы.
Интересны детали?
Смотрите запись вебинара на нашем канале:
Rutube
И обязательно подпишитесь на нас в социальных сетях, чтобы не пропустить новые полезные материалы, а также специальные акции для участников мероприятий.
